Recent posts:
-
Off Caffeine
-
On July 21, 2024 I stopped intake of caffeine of any kind.
I’ve been a coffee drinker most of my adult life. Cup or two of coffee every morning when I woke up, some other form of caffeine delivery in the afternoon. Lattes, black iced teas from Starbucks or Peets when I was on the road.
Years ago, I used to take a break from coffee for a month every year, but it had been a long time since that happened. I knew it was going to suck but it seemed like something I should try.
Initially I got the headaches as one would expect, the low energy, the feeling that something was missing. I quickly realized that one of the somethings that was missing was a warm drink in the morning. That “something warm in the morning” was just as much a habit as the intake of the caffeine. So I purchased some herbal teas (no caffeine) and started having a cup or two of those in the morning.
The amazing thing about this initial period was how calm I felt throughout the day. My blood pressure dropped significantly as a result of taking caffeine out of my diet, and I was falling asleep easier at night, sleeping better, and waking up much easier in the mornings. The calmness has persisted.
Once I was over the bulk of the caffeine withdrawal, no more headaches etc, I started to notice how low my energy levels were. This concerned me a bit, was it going to stay like this forever? I’m happy to report that this is no longer a “thing” in my day. I don’t noticed any dimished energy levels in my day, in fact I’m very steady at a level seemingly consistent with (and perhaps a little higer than) the caffeinated version of me.
There’s been a few additional benefits that have come out of this as well:
- I tend to just get up and go now, there’s not really a morning ritual of waking up. I just get up and get started with my day.
- I went camping recently and didn’t have the ritual of making coffee to contend with, in fact, I skipped tea one of the mornings because I was focused on getting out and fishing. I expect this will pay bigger dividends while backpacking as it’s less stuff to bring and clean-up when I’m in the backcountry.
- I really only drink water anymore, coupled with me stopping my alcohol intake at around the same time as my caffeine intake I’ve just been drinking water, tea, or electrolytes with no sugar in them.
Overall, the experiment has been a success thus far, and I haven’t found a compelling reason to start drinking any form of caffeine, nor do I have cravings for it anymore.
| tags: [ life health experiments ]
-
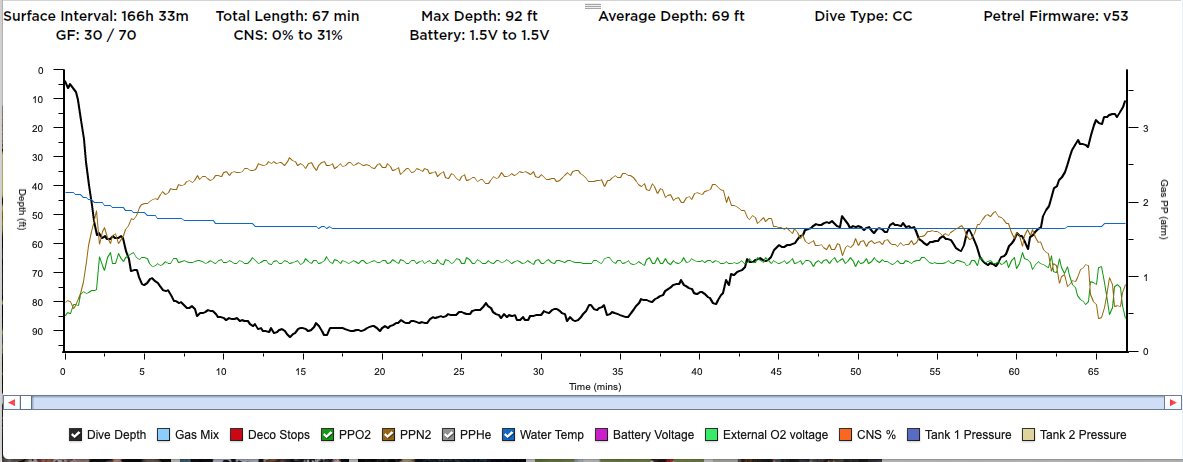
Dive Report 2020-SEP-20
-
Took the rebreather down to Monterey on Sunday for some diving. I arrived an hour early to give me time to do a final check, get my pre-breath done and get everything organized before Dave arrived with the boat. This time I tried no water an hour before bed and no coffee in the morning, this was to try and avoid unnecessary bladder discomfort while diving in the drysuit.
Anyways, I started my pre-breathing and something seemed off, so I bailed out and recalibrated. Once I was convinced everything was good I restarted the pre-breathing making it through with nothing amiss and no “off” feelings. Once done, I got everything else ready to go and by that time Dave had arrived. Josh and I put our stuff in the boat while it was still in the parking lot. Dave launched the boat and we were off.
I need to track down the name of the site we were at but we dropped in and hit about 60 feet on the top of some rock formations. The bottom around the rocks was around 80-90 so we spent about a 1/2 hour poking around then started to make our way back up the rock formations.
Water temp was about 52f at depth, visibility wasn’t great at the surface but opened up at around 50ft. Saw a bunch of nudis, and a giant chunk of fiberglass sheeting wedged vertically in a rock with a bunch of life growing on it. Didn’t see any jellies but felt the burn on my face after the dive was over. Good Dive.
On the way back we motored past a dead sea lion that has been floating on the surface for a while. It was NOT a pleasant smell.
A few things I worked on for this dive:
- I put in some cheater lenses into my mask so I could see the HUD more clearly, that really helped quite a bit. I’m curious to see how well they work while shooting video, because the image preview window has been blurry the last few years so sometimes my videos don’t come out. When I was washing gear at the end of the day one of the cheater lenses came off so I’ll need to put it back on.
- I strapped on the ScubaPro g2 as a backup computer for this dive, set it for Close Circuit (CCR) mode and took it with me. By the end of the dive it was convinced I was dead so I need to see if I can get the algorithms/conservancy closer to the prism computer so I can use it as a backup. More research/work needed there.
- I took a few pounds off because I sank like a stone last weekend. The weight loss over the last six months has been playing havoc with my weighting (in a good way). I am still heavy but it’s getting closer.
- More buoyance work with the tri-lam, it’s getting better, but it’s not quite as mindless as I’d like it to be.
- I tried strapping my bcd hose right along the loop on the outside, seems like a more natural position. Just a bit easier to locate and grab. Last time I had it inside of my loop and when I was stripping gear at the end of the dive the inflate button got wedged on for a few moments. Would prefer to avoid a similar situation at depth.
Before the next dive with the rebreather:
- dig into the algorithms/profile settings on both the main computer and the backup computer
- look at putting Oetiker clamps back on fitting that had previous clamp failure
- put together some rigging (probably just a caribiner) for leaving the machine in the water while I get into the boat.
- look into a shutoff valve for the OPV so I have a way to shut it off in the event that it fails
My next dive will probably be a skills dive, I need to spend some more time working on my deco procedures:
- shooting bags
- stop simuation with hangs
- buoyancy with the rebreather.
- perhaps do a dive with the camera to add some more multitasking load
Dive Profile
| tags: [ diving ]
-
SYS64738
-
Well I did it, again. I’ve changed the mechanism by which I manage this website. I am now using hugo along with a very simple theme that I find myself modifying to meet my whims. I do like moving back to the website being a bunch of simple (markdown) files instead of powered by a database and constant runtime renderings. Rendering static files and having those files served from a simple nginx instance with no dynamic languages (so far) feels better at this time.
I can hear my one reader protesting, “but without wordpress there won’t be a mechanism for me to be able to comment on your posts”, to which I reply “even better”. I’m sure it’s great for a lot of folks to give readers the ability to comment on their posts, and to engage in lengthy dialogs but I have never found it to be particularly comfortable, and I’ve found that for the most part, I spend most of my time cleaning out spam not engaged in compelling conversations.
I am still trying to figure out how to structure the content for this site to make it easily navigable but have opted to give myself the chance to just generate content until such time that I figure out how I really want it all to lay out. Hard to sculpt when you have no medium.
| tags: [ general ]